在创建Hbase表的时候默认一张表只有一个region,所有的put操作都会往这一个region中填充数据,当这个一个region过大时就会进行split。如果在创建HBase的时候就进行预分区则会减少当数据量猛增时由于region split带来的资源消耗。
HBase表的预分区需要紧密结合业务场景来选择分区的key值,每个region都有一个startKey和一个endKey来表示该region存储的rowKey范围。
创建包含预分区表的命令如下:
> create 't1', 'cf', SPLITS => ['20150501000000000', '20150515000000000', '20150601000000000']或者> create 't2', 'cf', SPLITS_FILE => '/home/hadoop/splitfile.txt'/home/hadoop/splitfile.txt中存储内容如下:201505010000000002015051500000000020150601000000000
该语句会创建4个region:
startkey endkeyregion0 - 20150501000000000region1 20150501000000000 20150515000000000region2 20150515000000000 20150601000000000region3 20150601000000000 -// region0没有startKey// region3没有endKey// 当put的一条数据rowKey值为20150516000000000时则会放入region2中
从HBase的Web UI中可以查看到表的分区
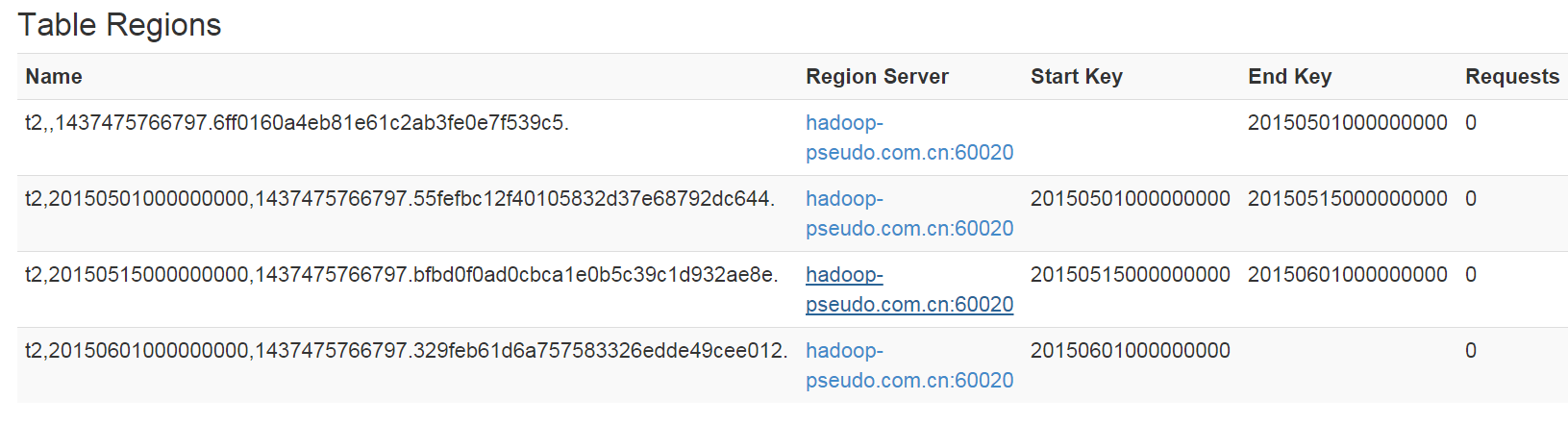
每个region的命名方式如下:[table],[region start key],[region id]